Accidentally Quadratic: Python List Membership
We had a performance regression in a test suite recently when the median test time jumped by two minutes.
We tracked it down to this (simplified) code fragment:
task_inclusions = [ some_collection_of_tasks() ] invalid_tasks = [t.task_id() for t in airflow_tasks if t.task_id() not in task_inclusions]
This looks fairly innocuous—and it was—until the size of the result returned from some_collection_of_tasks() jumped from a few hundred to a few thousand.
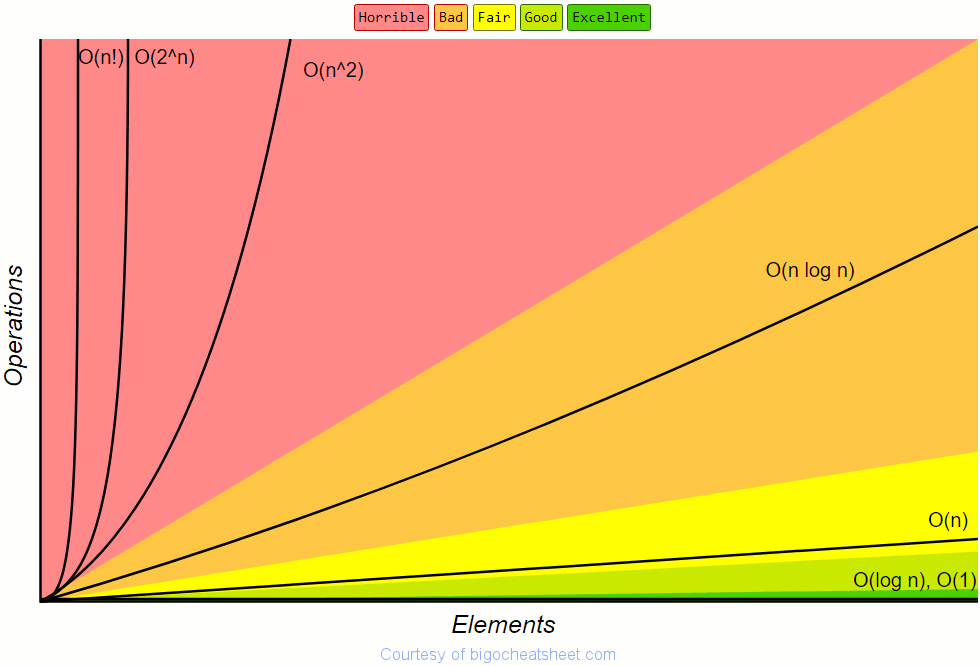
The in comparison operator conveniently works with all of Python’s standard sequences and collections, but its efficiency varies. For a list and other sequences, in must search linearly through all the elements until it finds a matching element or the list is exhausted. In other words, x in some_list takes O(n) time. For a set or a dict, however, x in container takes, on average, only O(1) time. See Time Complexity for more.
The invalid_tasks list comprehension was explicitly looping through one list, airflow_tasks, and implicitly doing a linear search through task_inclusions for each value of t. The nested loop was hidden and its effect only became apparent when task_inclusions grew large.
The list comprehension was actually taking O(n2) time. When n was comparatively small (a few hundred), this wasn’t a problem. When n grew to several thousand, it became a big problem.
This is a classic example of an accidentally quadratic algorithm. Indeed, Nelson describes a very similar problem with Mercurial changegroups.
This performance regression was compounded because this fragment of code was being called thousands of times—I believe once for each task— making the overall cost cubic, O(n3).
The fix here is similar: Use a set instead of a list and get O(1) membership testing. The invalid_tasks list comprehension now takes the expected O(n) time.
task_inclusions = set( some_collection_of_tasks() ) invalid_tasks = [t.task_id() for t in airflow_tasks if t.task_id() not in task_inclusions]
More at Understanding Big-O Notation and the Big-O Cheat Sheet.